
识别软件架构问题
像人体会发烧、咳嗽、疼痛一样,软件产品不健康时也会给出各种各样的信号来告诉我们软件架构已经存在问题,要抓紧解决。那么,有哪些信号可以帮助我们识别到软件架构已经面临健康问题了呢?我们可以从软件产品的使用者,生产者和需求方三个不同的视角来寻找一些线索:
- 产品使用者频繁反馈产品质量问题 最直接的信号就是终端用户的反馈,当软件产品上线后,终端用户会立即使用到最新的产品。如果每次更新后,都会有很多用户反馈使用过程中的问题,开始抱怨产品难用,甚至是比较严重的质量问题,那软件架构大概率已经腐化,需要赶紧采取措施。
- 产品生产者很难实现新需求 另一个信号是当有新需求时,产品生产者基于当前的软件架构已经很难实现,如果非要实现只能进行大范围的重构,或者通过各种其他方案来绕开改不动的部分,曲线救国,但这只能不断增加系统的复杂度。
- 产品需求方无法描述业务全景 从产品需求方的角度,架构的腐化和复杂度的提升也体现在业务的复杂性上,这两者是相互影响,相互增强的,任何一个业务需求都会因技术实现带来额外的影响,这种影响可能是好的,也可能是坏的,并且会反应在下一个业务需求的设计决策上。坏的影响会让新的需求实现起来更加复杂,而复杂的需求也会加重设计的复杂。当架构复杂到一定程度,也说明了业务复杂度很高,外在表现就是连产品需求方也很难说清所有的业务逻辑,经常需要通过开发人员从具体的实现代码中查找细节。
定位软件架构问题
IEEE 1471定义软件架构为:
Architecture is the fundamental organization of a system embodied in its components, their relationships to each other, and to the environment, and the principles guiding its design and evolution. 架构是系统的基础组织形式,体现为其组件、组件间的关系以及环境,架构也是指导系统设计和演化的原则。
在这里环境通常指的是系统的运营、组织结构等,对软件系统架构会产生非常关键的影响,本篇文章暂不考虑环境问题,只讨论技术层面的软件架构治理,重点关注系统中的组件以及组件之间的关系。要解决组件和组件之间的问题,就要找到组件的职责和边界,以及各组件之间依赖关系和应有的集成方式,并对照当前的架构实现成的样子,找到病因,对症施药。
组件的边界和职责
当系统变得庞大时,要搞清楚每个组件的职责和边界不是件容易做到的事情,毕竟系统的庞大不是一天两天做到的,需要经历多年的需求开发,人员的更替,多系统的集成等等。庞大软件系统的维护通常也不是一个部门可以做到的,要搞清楚这个系统中每个组件的职责,找到组件之间的边界,只能跨部门找到相关的人,通过协作的方式来逐步分析完成。
比较快的方法是从问题出发,逐个击破,这种方式目标明确,参与的人动力也比较足。问题可以从前文提到的信号中收集和整理,然后进行优先级排序,从优先级高的开始入手。
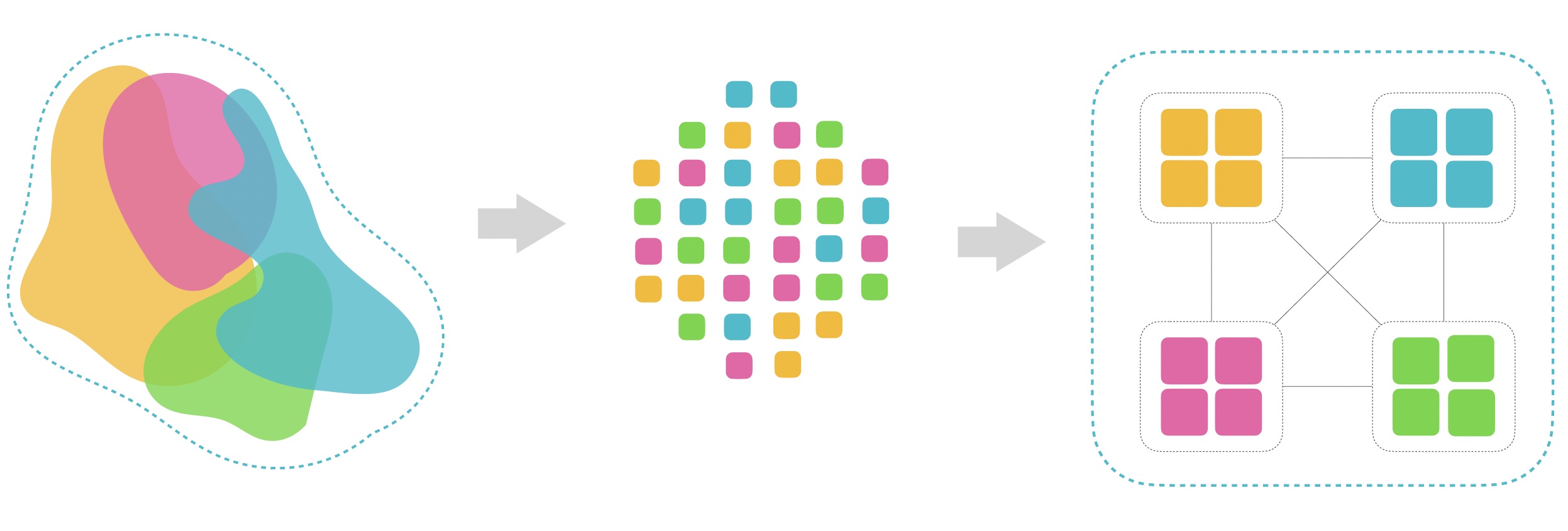 识别组件的边界和职责问题,就是针对业务重新进行建模的过程,找到不同的业务上下文和边界。我比较推荐的两种方法如下:
识别组件的边界和职责问题,就是针对业务重新进行建模的过程,找到不同的业务上下文和边界。我比较推荐的两种方法如下:
1. 基于DDD的限界上下文划分
在DDD的落地过程中,事件风暴作为一种快速有效的领域建模实践,被大家广泛采用。事件风暴通过命令风暴、寻找聚合、划分子域和限界上下文等步骤,组织业务人员、领域专家、架构师、开发人员、测试人员等关键角色,通过工作坊的形式,快速探索复杂业务并达成一致,找到业务组件及其边界,是一种非常有效的方式。大部分微服务架构落地前的 微服务拆分 都是采用事件风暴来进行的。
2. 基于8X Flow的业务建模
8X Flow是Thoughtworks CTO徐昊依据自己多年的实践经验,由他的四色建模法演进而来,是一种专门针对业务建模的方法。这种建模方法主张通过合同及合同的履约来理解业务,合同是最小的业务上下文,权责履约是最小的业务交互。那么如果我们找到在业务中的各个权责关系和合同上下文,就可以找到业务的边界。这种方法具有一旦理解,很容易上手操作的优点,在实际的落地过程中也有比较大的优势,适合以业务流程为主的系统建模,也可以作为 微服务拆分 的依据。
找到了软件架构该有的样子,那么再结合当前的组件划分和组件职责,就可以找到其中的问题,产出对应的解决方案,并根据每个方案的投入产出比进行进一步的实施优先级划分。典型的问题通常会有下面几类:
- 组件中维护了不属于当前组件职责范围内的数据和模型,需要重新定义归属范围。
- 组件中维护了多个完整上下文的数据和模型,且上下文都很复杂,这种情况下需要进行组件的拆分。
- 一些组件因为技术实现原因被拆分开,在完成某些业务逻辑时需要紧密合作,经常面对一些数据一致性的问题,这些组件就需要进行合并。
组件的依赖关系和集成方式
有了组件的边界,各个组件的关系往往也就出来了,比如在DDD的事件风暴后找到的限界上下文映射图中,是有各个上下文的上下游关系的,我们可以基于此来定义组件之间依赖关系和集成方式。
那另一个难题是理清楚现有系统各组件的依赖关系,这个远比找到现有系统应该有哪些组件要难得多,因为系统一旦复杂到需要进行这样大的健康检查,就没有人能说的清其中的细节逻辑,更有各种循环依赖,让人晕头转向。对于已有的系统,也有一些办法可以帮助我们理清现在的组件之间的关系:
1. 引入Tracing工具
现在有很多开源的Tracing工具,如jaeger、SkyWalking等,当系统的各个组件都集成了这些工具,就可以找到各个接口的完整调用链路,通过这个调用链路的分析,就可以轻松的找到各个组件间的关系。
2. 通过静态代码扫描来找到服务间的依赖
如果没有集成Tracing工具,并且集成的可操作性不大,那可以通过静态代码扫描的方式来进行分析,找到组件之间的调用关系,输出成组件依赖关系图。特别是针对一些通过消息队列等异步消息中间件进行集成的组件,这种方式会更加有效。但这种方式有个缺点,就是所有组件之间的调用方式都要采用相同的实践才行,如果不遵循相同的规范,很难定义出一种规则找全所有的调用关系。
然而,即便有方法可以做,也不能期望通过上面的方式百分之百找到所有的依赖关系,毕竟多数情况下,我们做这个事情的前提是面对一个已经腐化的复杂的遗留系统。
故事才刚刚开始
识别和定位到一个腐化的、复杂的、不健康的软件系统架构问题,只是一个开端,但万事开头难,开头也最重要,如果没能识别到架构上关键的问题,没有找到病根,头痛医头,脚痛医脚,架构师也就成了庸医,不仅不能治病,还会贻误病情。